CAP Twelve Years Later: How the Rules Have Changed
TL;DR
- CAP的三者只能滿足其二被過度解釋,三者取其二的是需要perfect availability或是perfect consistency的情況。
- 現實中,我們很少需要perfect availability或perfect consistency,而是在三者間決定一個可接受的比例。
- 承上,我們甚至可以根據情境來決定是要availability多一點,或是consistency多一點。
Why "2 of 3" is Misleading
- 現實中,network partition發生的頻率不高,大部分時間我們可以兼顧C跟A
- 即使碰到了,根據設計的粒度,C跟A的選擇也不止一次,例如不同的subsystem可以各自決定,甚至可以根據data的類別來決定
Latency
在CAP原本的理論不考慮latency,但laytency跟partition有很深得關聯,因為我們通常使用timeout來決定partition是否發生,所以很高的laytency就很容易進入partition mode。相同的,很低的timeout,也很容易進入partition mode。
Managing Partition
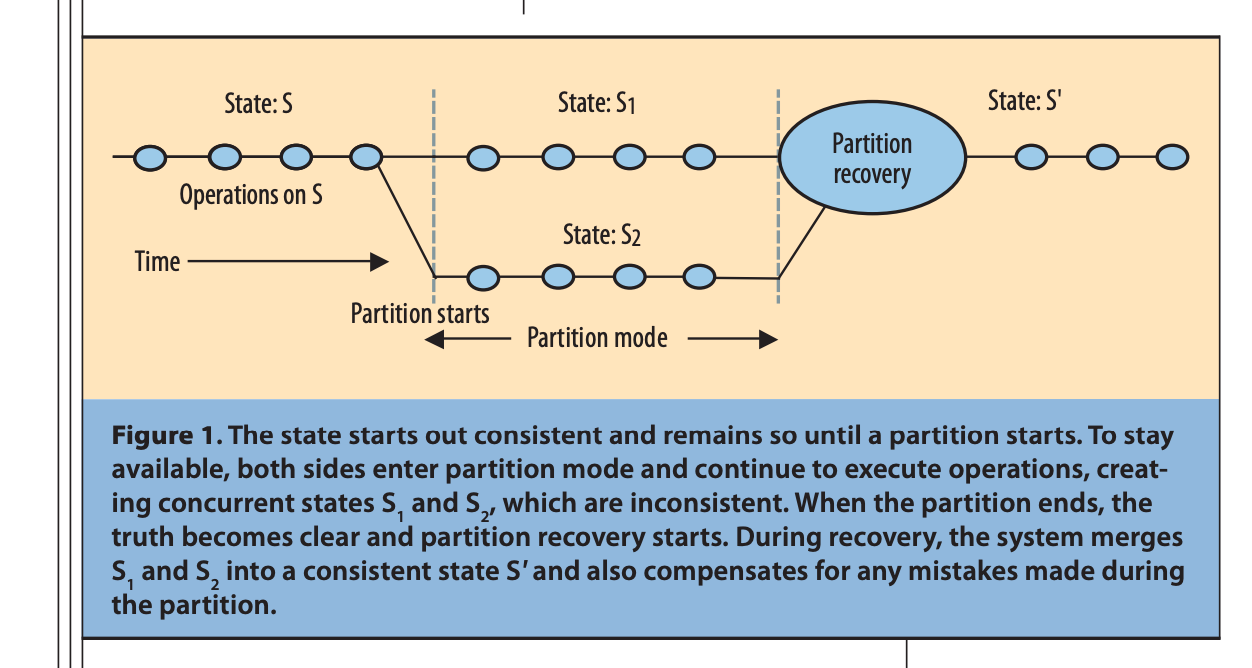
正常狀況
我們可以正常的執行,並且獲得我們需要的C和A
Partition Happened
要能處理partition,首先要能知道partition發生,並且系統進入partition mode。
在partition mode系統有兩種選擇:
- 保持某些invariant不能被違反。所以要拒絕請求(犧牲availability),甚至關閉某些子系統
- 讓partitions各自處理,之後在嘗試recover,在此有些手法可以用:
- CRDT
- Version Vector
- Compensation
CRDT和Version Vector嘗試紀錄額外的資訊,期望在recovery的時候,讓資料可以merge。
Recvoery
當partition被修復了,就可以嘗試merge在partitioned時候產生的inconsistency,在data有衝突的情況下,例如機票overbooking,就可以考慮由商業手法來解決,例如致電給其中一位消費者,告知他的定位被取消,並給予補償。