Megastore: Providing Scalable, Highly Available Storage for Iteractive Services
Introduction
Google推出管理分散式transaction的storage,底層的storage是bigtable,在bigtable上面加上Paxos、2PC等處理consensus的演算法。
總結來說,Megastore將每個data partition稱為entity group,entity group的操作是synchronous,且保證ACID並支援到serializable的isolation level。
在entity group之間,Megastore建議透過queue的機制來溝通,但也有提供2PC的機制。
設計思維
在R&D的時候,RMDB的ACID semantic比較直覺可以加速開發,但是scability不好。NoSQL能scale但要處理consistency的問題。
類似DDD的思維,model之間的relation讓他們能group在一起,並且有一個類似DDD aggregration root的存取點(在megatore稱為entity group)。
很多時候只是需要以aggregration為單位的strong consistency,並不需要global的strong consistency,所以Megastore以entity group為單位保證strong consistency,但是entity group之間只保證weak consistency。
Architecture
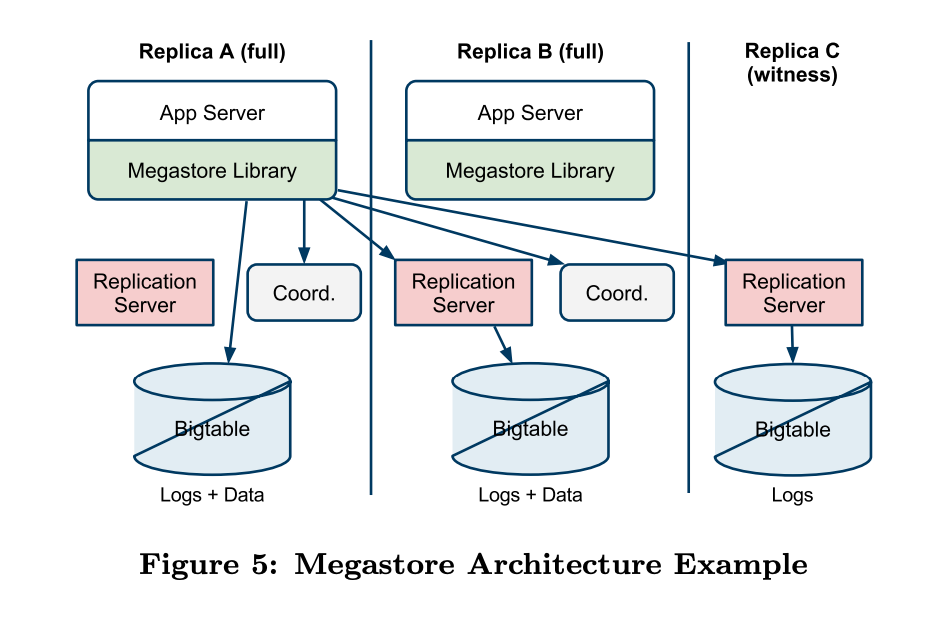
Replication
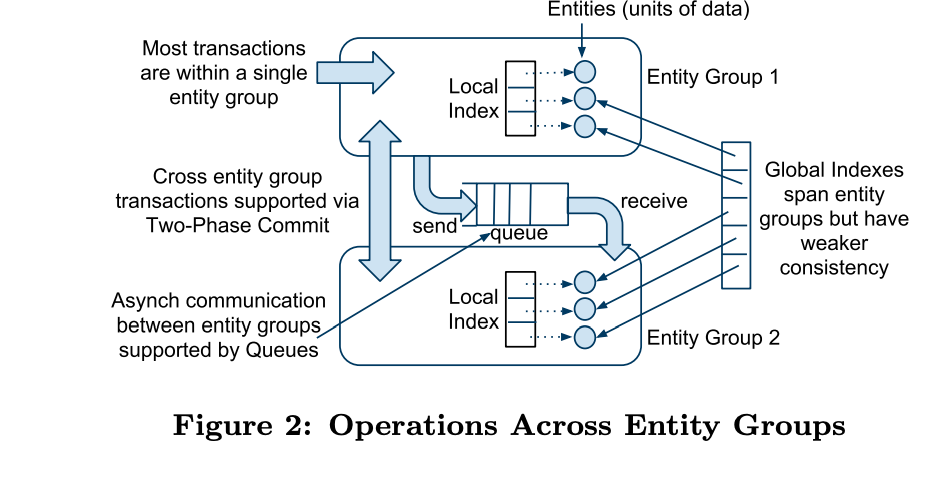
Inter-Entity Group
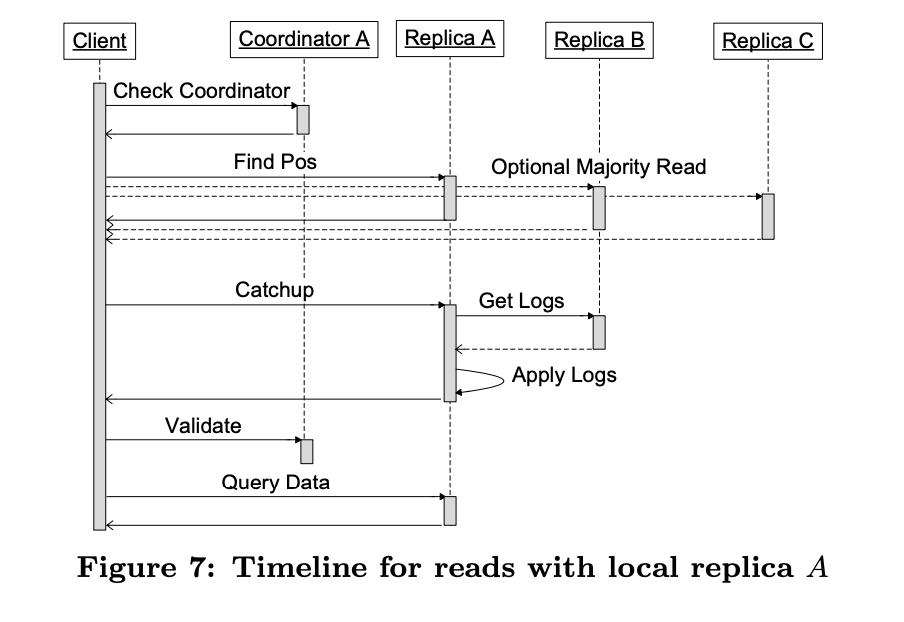
Fast Read
在大部分情況下,entity group的replica都是syncronized,所以都可以local read。但少數真的有些沒跟上的話(node failure之類的原因),會做remote read順便catch up。
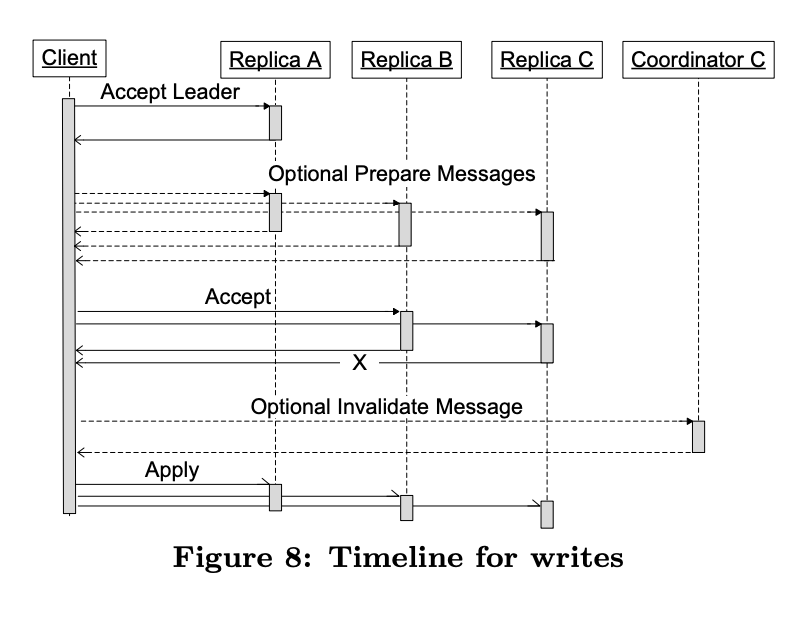
Fast Write
基本上基於Paxos,但是參考了只要一個roundtrip的作法,直接先做propose,失敗了在fallback回2 phase的Paxos。
但一個roundtrip的做法需要一個master,所以會引入SPOF,所以這邊的設計是多個master(稱為leaders),每個leader負責一個log的position,就算leader掛了也只是skip那個log position。
Intra-Entity Group
提供了queue跟2PC,但推薦除非真的需要synchronous,否則推薦用queue,(https://en.wikipedia.org/wiki/Two-phase_commit_protocol)的效能較差。
Data model

Pre-Joining with Keys
在Megastore,可以定義schema,並且宣告某個table為group root,entity group之間的關係透過key來做join。
local index
Local index存在每個entity group的replica,local index支援ACID和serializable的isolation level,有storng consistency。
global index
Global index不保證strong consistency。