Spanner: Googles's Globally-Distributed Database
TL;DR
Motivation
Big Table雖然可以支援非常大量的讀寫,但是它是 key-value的 storage,schemaless且無法支援transactional,而且Big Table是eventual consistent,不是strong consistent。
另外一個選擇是MegaStore,MegaStore支援sema-relational data model和synchronous replication,但write throughput 不好。
為了滿足Google的廣告業務需求,需要一個high throughput、transactional而且globally consistent的backend storage。
Architecture
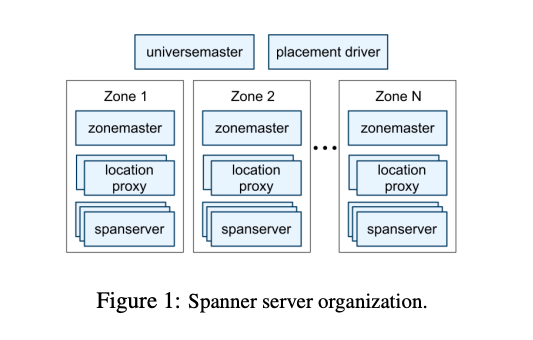
universemaster
Display各個zone 的 console
placementdriver
負責resharding,從各個zone之間搬移資料。
zonemaster
指定Data要存到哪個spanserver
spanserver
Serve data給client
Spanserver stack
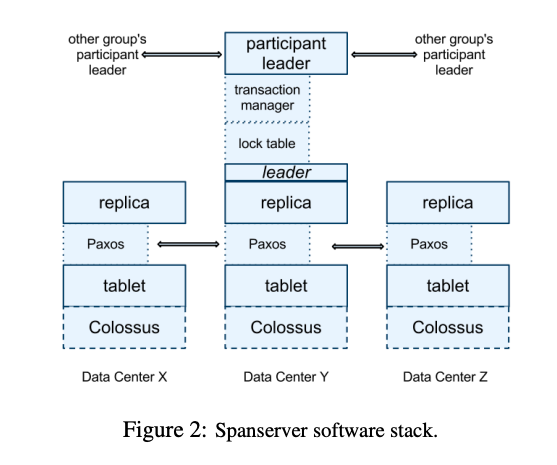
Colossus
tablet底層的data structure,用到B-Tree like和 WAL的技術來保存資料。可以參�考 Colossus under the hood: a peek into Google’s scalable storage system
tablet
類似Bigtable的tablet,也是KV的data model,但是每個key含有timestamp,所以可以做到versioning。
paxos
每個spanserver都有一個paxos state machine,paxos state machine儲存paxos的metadata和log。
replica
replica利用paxos來處理replicate,每個replica leader可以接受write request,而非leader的replica只能接受read request。
leader
如果一個replica是leader,它會keep一個lock table,lock table裡面存被lock 的key range。同時每個leader也會有一個transaction manager,然後跟其他spanserver leader共同keepdistributed transactions,這些leader其中之一會被選為participant leader,其他的leader是participant slave,然後負責同步paxo group裡面的資料。
Data Model
Spanner基本上還是KV的儲存方式,但每個primary key會mapping到cloumns,而且這些primary key會排序,並且可以倔由語法指定關聯的data放在一起,因此可以指定locality,增進讀取的performance和thourghput。
TrueTime
因為time skew的關係,所以時間是無法精準的,Google藉由給予timestamp一個誤差值,來表示可能的時間範圍,只要兩個timestamp,重疊,就視為conflict,否則就可以比較先後。
為了盡量去壓縮時間的誤差範圍,Google在每個data center都部署好幾個原子鐘(atomic clock)和GPS,這些server會彼此同步時間,來降低time skew的誤差值。
Concurrency Control
Paxos Leader Leases
Paxos一次只會有一個leader,每個想要成為leader的node會send lease votes,如果它蒐集到quorum的vote,就變成leader,舊的leader如果想繼續當leader,會在快結束的時候send lease votes。
每個leader都會有一個,下一個leader必須等到經過以後,才可以上任,並且舊的leader要主動退位。
RW Transactions
Read Write基本上用的是2 phase commit。每個commit只有在以後,其他replica才看得到,這樣做其實就是等確定time skew帶來的誤差消失以後,才讓此次的commit visible。
當client要commit的時候,它會挑一個coordinator group並且對裡面的participant leader送commit message。非 coodinator leader跟在自身最後一個transaction的timestamp來決定這次timestamp送給coordinator,並進入prepare階段,coordinactor 不用進入prepare階段,但會從這些timestamp裡面挑出一個timestamp,當作這次commit的timestamp,然後所有node進入commit階段。
RO Transactions
每個replica會keep一個timestamp ,如果一個read request時間 < ,就可以直接read data,但如果目前有prepare階段的transaction,則的職就是所有 prepare timestamp裡面的最小值-1。
Schema-Change Transactions
為了不要block整個系統,schema change會被assign一個未來的時間 ,並且在背後處理�。如果一個read的時間早於,就會被馬上處理,不然就要block到schema change完。